Digest: r/selfhosted: May 29 - Jun 05, 2026
Published: 3 weeks ago | Author: System
No posts in this digest period.
| ID | Type | Limit | Status | Last Update | Next Update |
|---|---|---|---|---|---|
| digest-selfhosted | digest | 8 | Disabled | 3 weeks ago | 2 weeks ago |
Published: 3 weeks ago | Author: System
No posts in this digest period.
Published: 1 month ago | Author: System
The reason many of these... creatures... post here, and on Reddit in general is for SEO.
Reddit ranks highly in search results, which humans and LLMs alike use.
I'm sure you have all seen the 'I have problem x, and have tried y and z. Curious what others are doing?' type posts. Then the promoted product is often (not always) inserted into the comments by an army of alt accounts sandwiched between actually good and established products to boost perceived authenticity further.
Anyway, it turns out you can simply comment about how bad their shit is, and since this makes their efforts backfire, they swiftly delete their own slop.
Delightful!
Screenshot below for reference
⬆️ 476 points | 💬 55 comments
https://www.reddit.com/gallery/1tnrwe0
We’ve crossed 3.6k+ users on GitHub, with 52 developers now contributing to the project — and we’re scaling faster than ever
Over the past few months, we’ve ported many of the web features directly into the native mobile app, so there’s no longer a need to switch between the PWA and mobile experience. The goal is simple: make SparkyFitness the only app you need to track your health & fitness.
If you haven’t tried SparkyFitness yet, I’d love for you to give it a shot and share your feedback. Since day one, almost every feature has come directly from this community’s suggestions and feedback.
Your input doesn’t just help improve the app for you — it helps thousands of other SparkyFitness users as well.
SparkyFitness can sync data from multiple health and fitness platforms:
⬆️ 491 points | 💬 53 comments
Android has long positioned itself as the open alternative to Apple's closed ecosystem. Many people chose Android for this openness and freedom to customize and alter your software. This is again under serious threat.
Google's new policy will block all apps from working, unless the developers register centrally, submit government-issued ID, pay fees, and hand over signing keys. Might sound reasonable at first, but this has many consequences. What is shocking: This applies to all apps being installed, not only from the Play Store. So even F-Droid is affected by this.
The practical consequences are bad. Any developer who doesn't comply, whether due to cost, privacy concerns, or simply being simple side project, will have their apps blocked from installation on all Android devices, including via sideloading. This means:
This directly affects our community. It is not certain that all app developers will pay the fee and use their national ID for this hobby project. Especially some of the privacy-focused projects might be affected.
There is technically still one way to side-load apps, but this is very tedious and includes a mandatory 24h cool down time, so you are really sure about the risks you are taking. Wtf.
This runs counter to the core values of open source and free software distribution. If you think about it, it is a real power play by Google that amounts to a form of cencorship: A company in the USA is dictating what software can run or cannot run on a device you own.
For more infos and what to do about it, check https://keepandroidopen.org/
⬆️ 463 points | 💬 206 comments
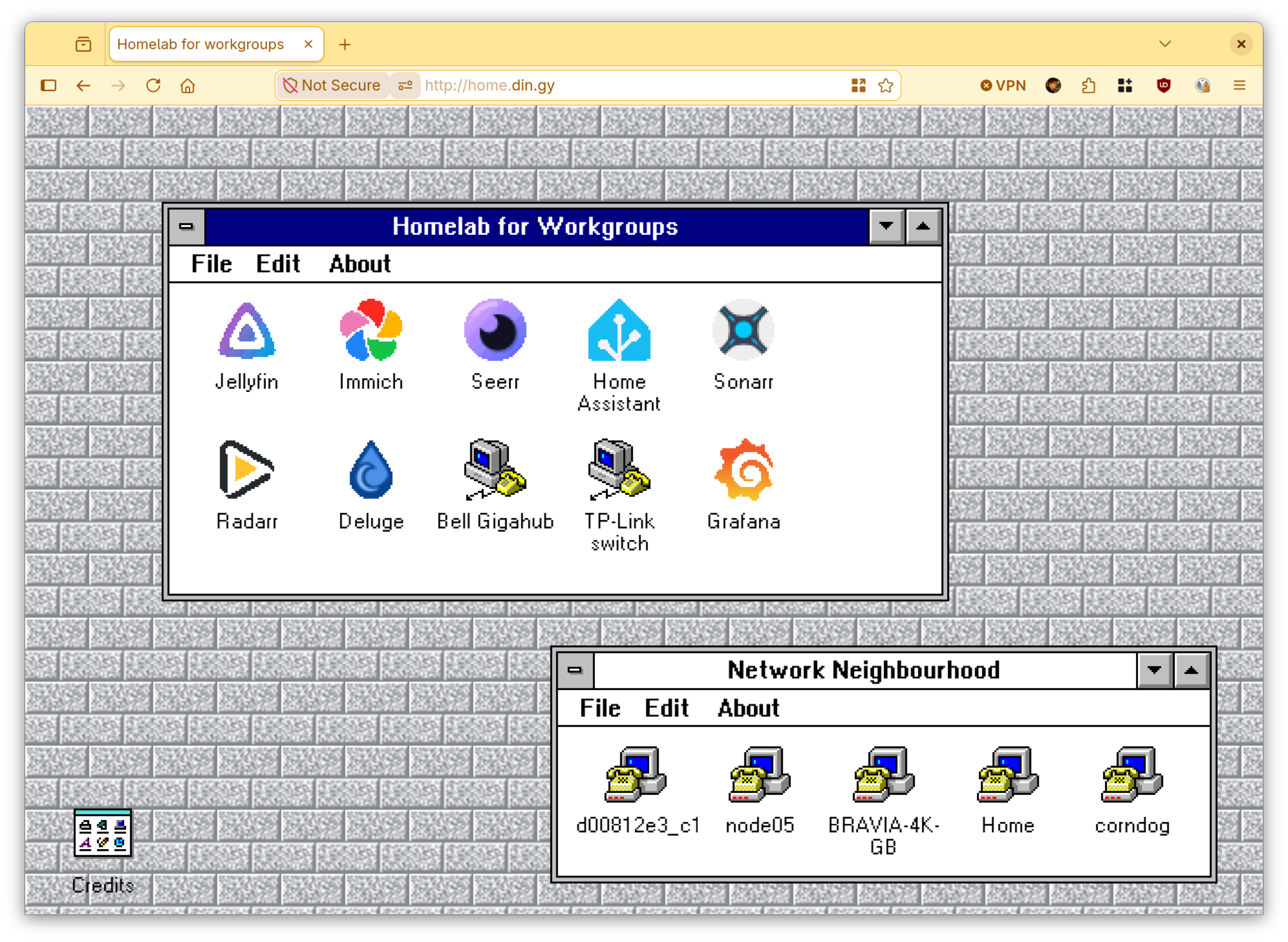
⬆️ 485 points | 💬 50 comments
Hi r/selfhosted, we have great news for all Homarr users here. Memory usage of Homarr has always been critizied - and we've heard you. A few weeks ago we opened a feature bounty and thanks to that, beginning from v1.62.0, you can expect between 40-60% less memory. We achieved this by merging node.js processes of the app, reducing allocations and tweaking next.js settings to save on memory. The speed and performance are unchanged - but now you can run Homarr with less than half that it previously needed. The new version has already been thoroughly tested, so you can update all your instances safely.
https://github.com/homarr-labs/homarr/releases/tag/v1.62.0
We also got some big improvements coming for better UX, better performance, better design and we are focusing on polishing the experience overall.
No AI was used in this post.
If you have questions, comment below and I will reply 👇
⬆️ 464 points | 💬 73 comments
"A malware-spreading scumbag swimming through GitHub pushed malicious commits to more than 5,500 repositories on Monday as part of an automated campaign called Megalodon."
Maybe it's time to stop updating until it's safe again ?
⬆️ 436 points | 💬 71 comments
Hi all, looking for recommendations for a self-hosted book management app that can handle a fairly large library (~150,000 books).
I’ve already tried CWA and Booklore/Grimoire, but both struggled a bit with UI lag and fairly high system usage at that scale. Recently I came across Kavita and BookOrbit. BookOrbit’s public demo seems to handle a huge library surprisingly well, but the project also looks pretty new in comparison.
Does anyone here run either of these with a very large collection? Mainly curious about real-world RAM/CPU usage, scan performance, and general responsiveness at scale. Any feedback would be appreciated.
Kavita https://www.kavitareader.com
Bookorbit https://bookorbit.app
⬆️ 412 points | 💬 178 comments
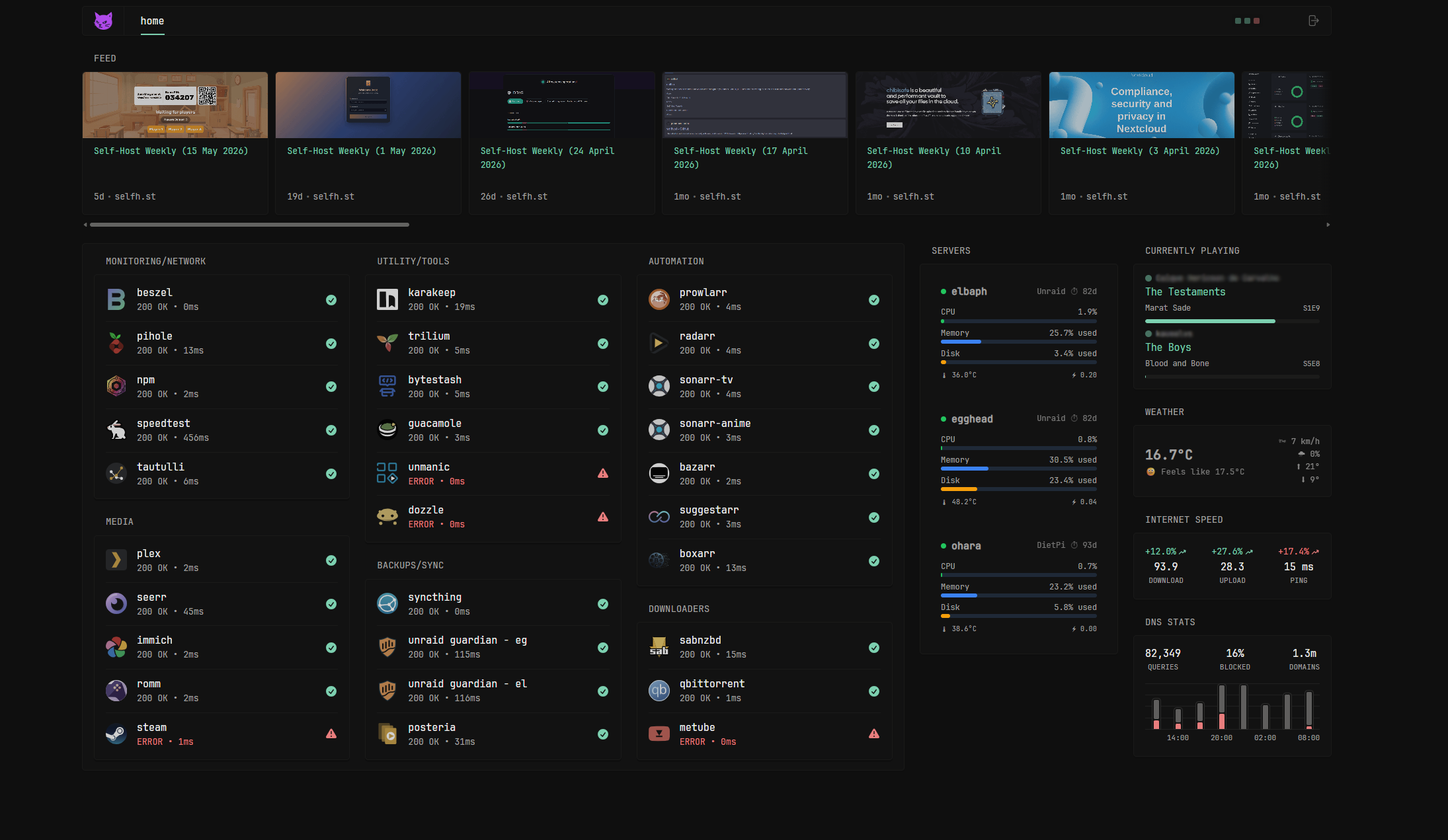
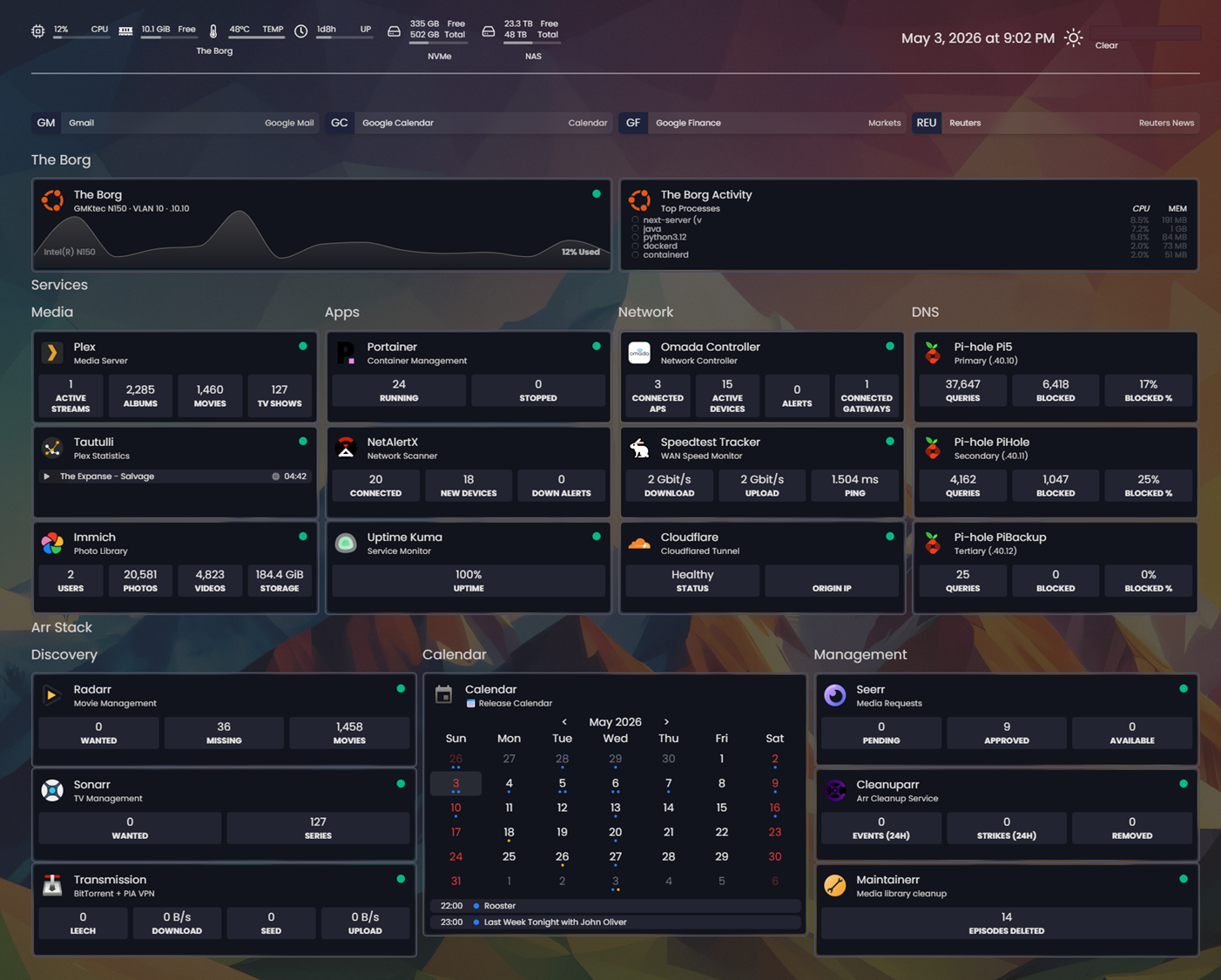
My dashboard after removing everything that is not important. One page, compact, all the information I need. Screenshot from last week.
The dashboard is Dynacat, a fork of Glance.
⬆️ 413 points | 💬 67 comments
Published: 1 month ago | Author: System

“His replacement, Michael Sullivan, former CEO of both Acquia and Insightsoftware, touts his experience with “all facets of mergers and acquisitions” on his own LinkedIn page, including experience working with leading private equity firms.”
There isn't any true evidence that Bitwarden will eliminate support for selfhosted versions and/or get rid of the options to use selfhosted servers in the apps, but it does have me a bit worried about Bitwarden in general in the long term...
⬆️ 1,592 points | 💬 253 comments
https://www.plex.tv/blog/new-lifetime-plex-pass-pricing/
⬆️ 531 points | 💬 888 comments

Recently upgraded from an open rack to an enclosed rack to keep tiny hands away from the flashy lights. They seem to enjoy it. The misses enjoys the services.
Currently running a 2 node proxmox cluster, 3 websites, Immich, Matrix, OCIS, Jellyfin, *arr stack, Home Assistant, and more to come.
⬆️ 328 points | 💬 58 comments
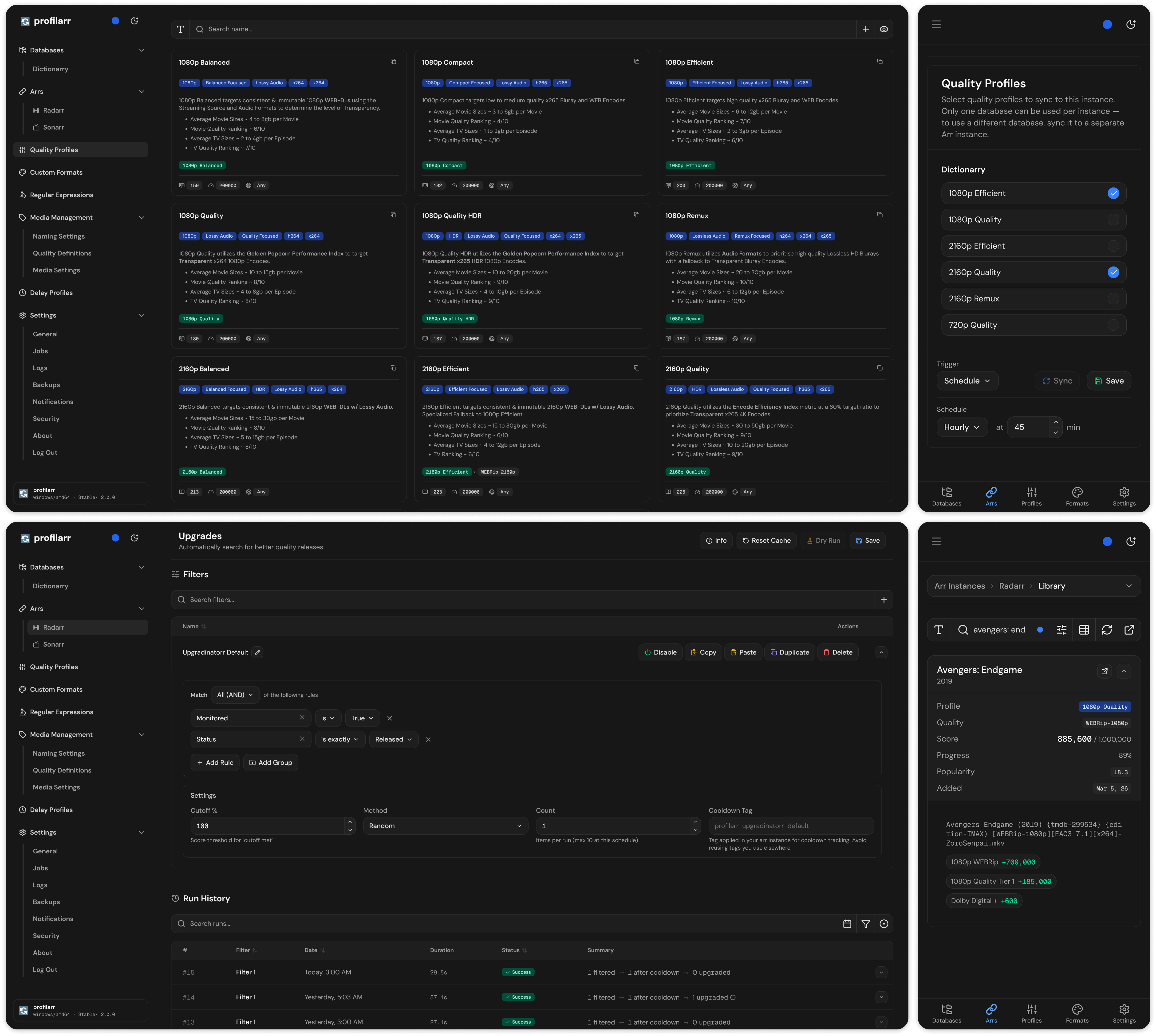
For those unfamiliar, Profilarr syncs quality profiles, custom formats, and media management settings from shared configuration databases into your arr Arr instances.
v2 has been in closed beta for a few months and is now publicly available!
v2 can connect to multiple databases at the same time. A few of the more popular ones:
The Arrs are great at reacting to new releases via RSS, but they don't continuously revisit older downloads looking for something better. This is especially important when you switch or update quality profiles and are left with releases that no longer match what the new profile would have grabbed.
Upgradinatorr solved this by cycling through your library and triggering searches over time. v2 brings that idea into Profilarr, with more control and a GUI.
You can filter by any metadata your Arr tracks: ratings, year, genre, size, release group, language, date added, and more. Filters support nested AND/OR logic, selectors let you prioritise what gets searched first, cooldowns prevent items from being repeatedly searched, and everything can run on a schedule.
v1 handled local changes through complex git-based three-way merges. v2 replaces that with a dedicated change layer: your local changes now live separately from the upstream database, which means updates can come in without overwriting your changes or forcing you through messy merge conflicts. In practice, that means fewer conflicts surface in the first place, and the ones that do can often be resolved automatically.
In addition to those major highlights, here are some smaller improvements:
v2 is not compatible with v1. The underlying database and customisation systems changed significantly, so existing v1 databases/configs/appdata won't work directly in v2.
If you want to try v2:
A few years ago I just wanted to share some quality profiles I thought people might be interested in. It's gotten a little out of hand since then... None of that is possible without:
You can follow the 2.x.x roadmap here. Some highlights from that include:
For those wondering about anime, there is no profile yet, but it's on the roadmap. The approach is a bit different from our existing profiles: instead of one profile that scores releases across your whole library, we're building per-series profiles based on manual rankings of the best release in each variety for each anime; similar to what SeaDex does, but across more formats (Blu-ray encode, WEB, Remux, dual audio, subs, etc.). This ties into the advanced profile automation work above; per-series profiles only work if each anime can be routed to its own profile automatically.
In the meantime, v2's multi-database support means you can run Dictionarry alongside any community-built anime database. TRaSH Guide's Anime profile is the most established option and what most users currently rely on. You can follow progress on our anime work here.
⬆️ 487 points | 💬 134 comments
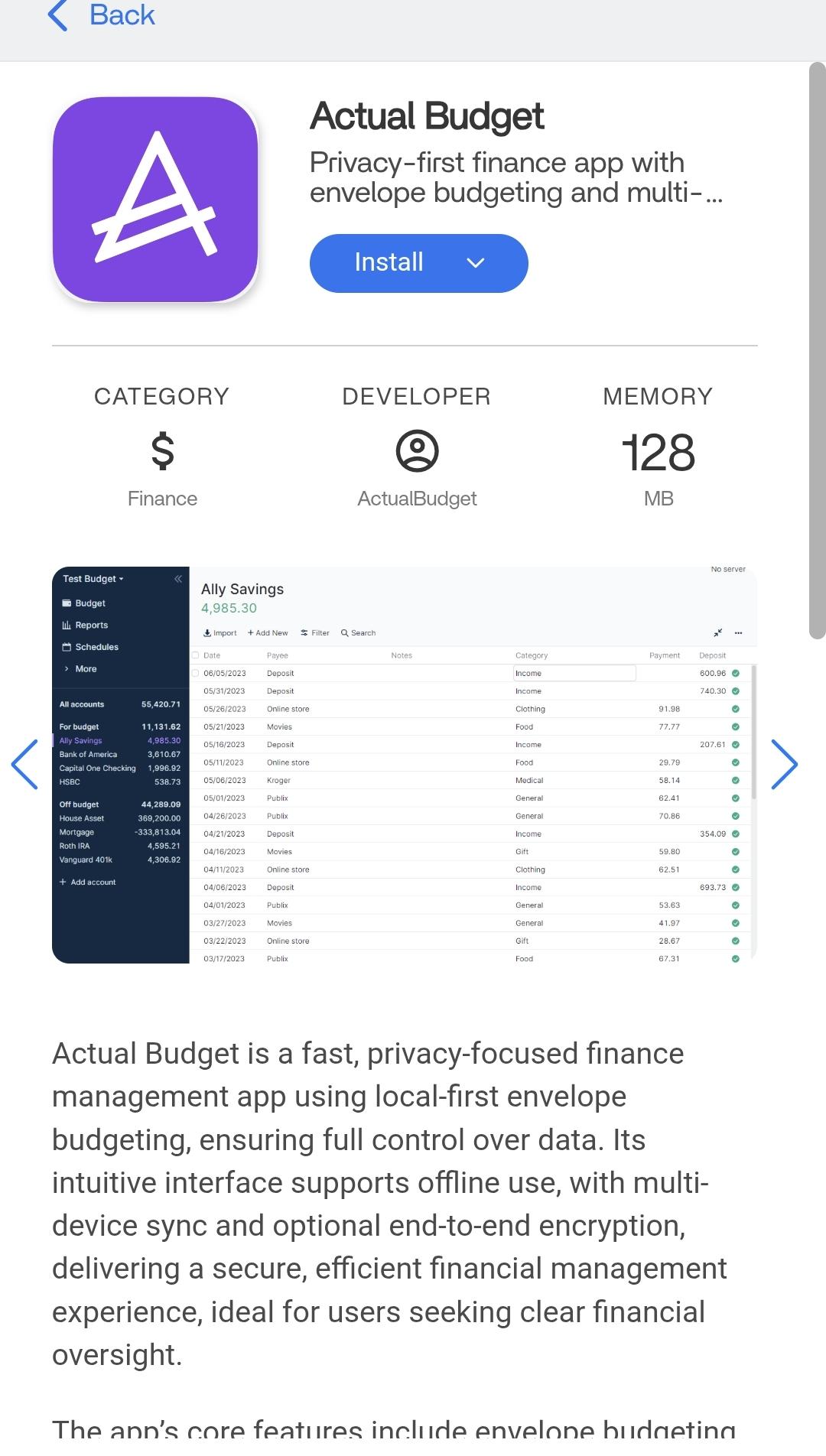
I have been looking at this since all the other apps that I have seen require a paid subscription to link banks and such. Im just curious to see how it works. I love a good budget app, yeah ive reached that stage in life. 🤣
⬆️ 350 points | 💬 197 comments
https://www.reddit.com/gallery/1tggftg
I modded my switch OLED a month ago and I couldn't resist connecting it to my server somehow. Well here it is, a game library so I can download any games I want directly from my server.
It's pretty easy to setup, Ownfoil as a server and Cyberfoil as a client. Pretty cool projects.
⬆️ 311 points | 💬 58 comments
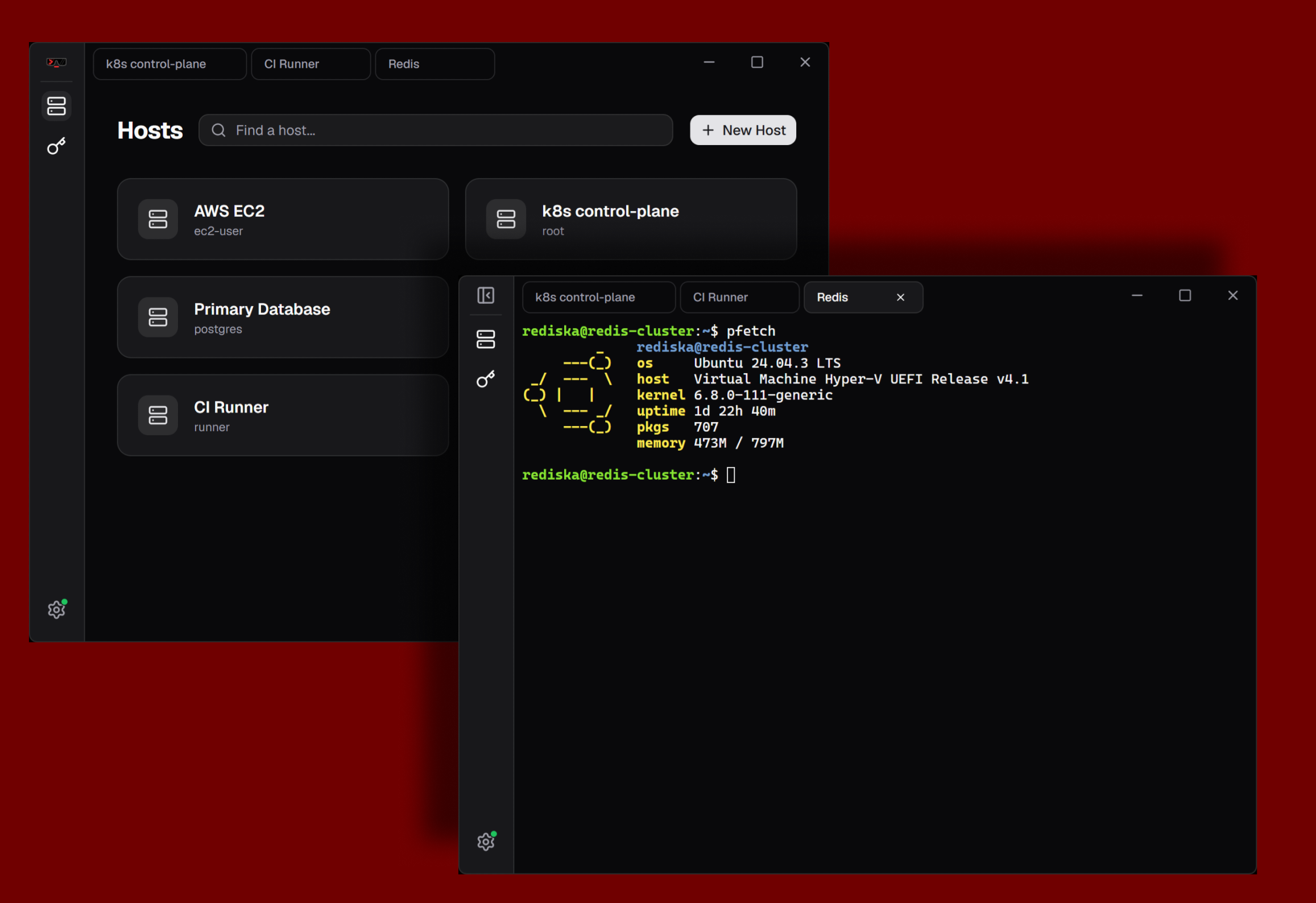
Discord: https://discord.gg/x7K9BRrQJE
Website: terminator.sh
Hey! We're launching Terminator, an open-source SSH client with a self-hostable sync server.
I like Termius, but the sync functionality is paywalled. I've had this idea for a while, and recently decided to build it as part of a team university project.
Here's how it works. When you interact with Terminator, all your host profiles, keys, etc. are encrypted (with a key derived from your password) and saved locally. When you decide to use a sync server, the client only uploads those opaque already-encrypted blobs! Of course, you don't have to use a sync server, the app is fully usable offline.
The desktop client is built on Wails and Go: it's lightweight (~15MB) and cross-platform (🪟 🐧 🍎)
Right now it's relatively basic, but there's a bunch of stuff on the roadmap.
(we also kind of have to launch it now due to uni deadlines 🤪)
Would love to hear your feedback!! (check out our Discord)
Get it here: terminator.sh
⬆️ 440 points | 💬 132 comments
Published: 1 month ago | Author: System

Found this and want to share it.
⬆️ 1,191 points | 💬 46 comments
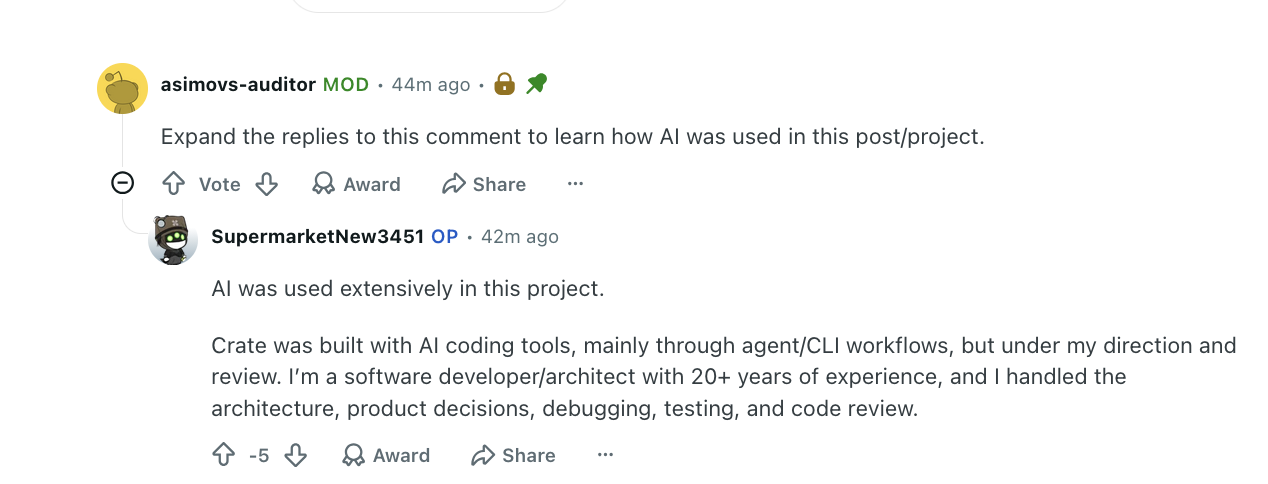
I understand and am against using AI without any idea of what is going on, but when the community pulls of things like this, the next time this person posts -- or if someone about to posts sees this -- what do you think they will be? Honest? No, and I won't blame them if I start to see false claims.
⬆️ 614 points | 💬 222 comments

⬆️ 715 points | 💬 58 comments

Needed daily home lab health reports.
Had a thermal printer laying around so I put it to use.
Still a work in progress, next is weekly maintenance reports and eventually AI to handle exception reporting.
⬆️ 694 points | 💬 85 comments
Docker bypasses UFW and exposed my database. Again. Writing this down so I stop forgetting.
Self-hosters, this one is for you.
I finish setting up a new app on my VPS, everything looks good, then I run a security check and boom. Same mistake again. Docker silently bypassing my firewall and exposing my database to the internet.
This has happened to me more than once. I keep forgetting it, so I'm writing it here as a reminder for myself and hopefully useful for someone else running their own server.
When you're using docker compose in production on a VPS, remember:
Don't expose database ports unless you absolutely need to. And if you do, don't do this:
ports:
- "5432:5432"
Do this instead:
ports:
- "127.0.0.1:5432:5432"
Why does this matter?
Docker manages network rules at a very low level on Linux. When you publish a port, it sets up routing rules directly in the system networking stack. So if you don't explicitly bind it to localhost, you're effectively exposing that service on the machine's public network interface.
And if you're thinking "it's fine, I have UFW enabled", not necessarily. UFW is just a frontend for Linux firewall rules, and Docker bypasses it by manipulating those rules directly. Your database might still be exposed even with the firewall on.
Has anyone else been caught by this?
⬆️ 321 points | 💬 194 comments
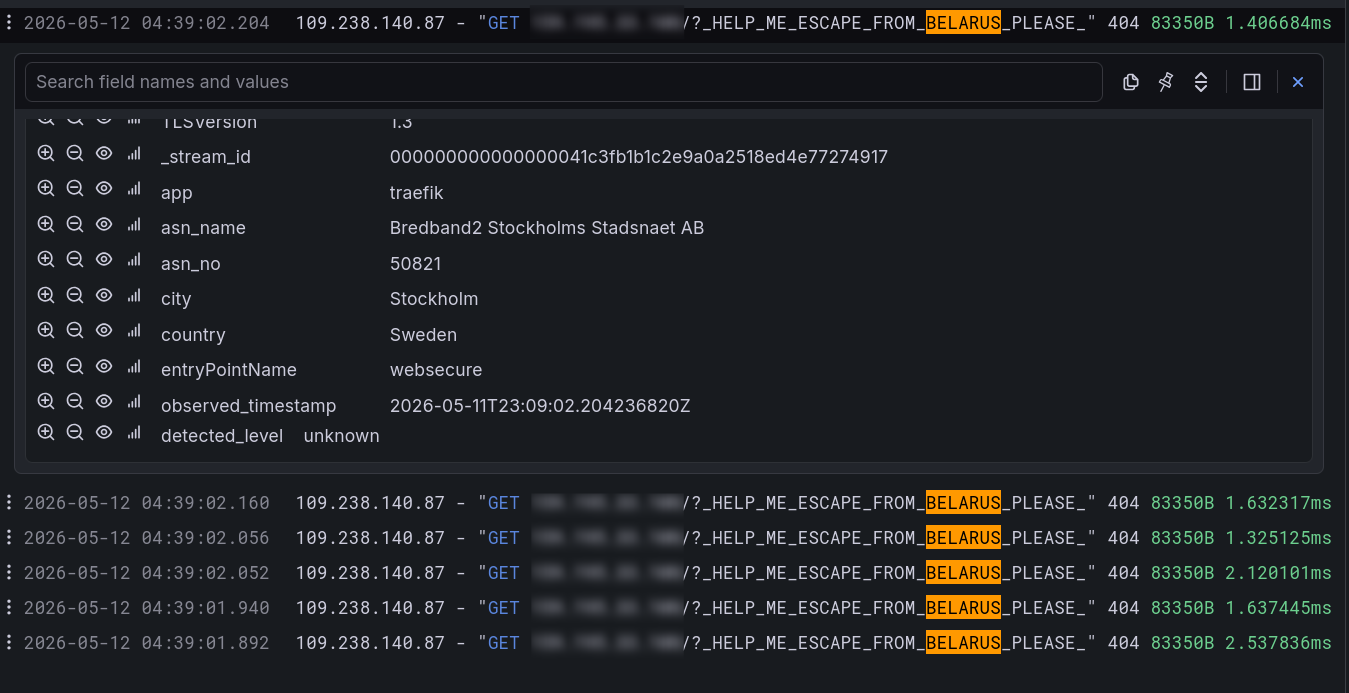
⬆️ 380 points | 💬 56 comments
Posting this as a PSA / confession because I almost had a heart attack last night and I figure if I got bit, someone else will too.
TL;DR: Replaced pangolin + NPMplus with a double-Caddy + WireGuard setup. Put a "clever" config on the local Caddy to minimize maintenance. Tested it once and called it a day. Two weeks later realized my entire LAN was reachable from the public internet via the wildcard tunnel.
I used to run pangolin (VPS) + NPMplus (local proxy for split DNS) to selectively expose my services. The setup worked fine, but having to click through two different web UIs every time I added a new service was offending my inner lazy engineer. So a few weeks ago I decided to replace them both with a double Caddy setup linked by a WireGuard tunnel.
The Caddyfile on the VPS side is a dumb catch-all that punts everything down the tunnel (first mistake):
*.mydomain.com {
route {
reverse_proxy http://10.0.0.2:9999
}
}
And the local Caddyfile:
# Listen on both the Tunnel (Port 9999) and LAN (Port 80/443)
http://:9999, *.mydomain.com {
map {host} {vars.is_public} {
public1.mydomain.com true
public2.mydomain.com true
default false
}
@vps_unauthorized {
expression "{local_port} == '9999' && {vars.is_public} == 'false'"
}
handle @vps_unauthorized {
abort
}
@public1 host public1.mydomain.com
handle @public1 {
reverse_proxy 192.168.1.100:8000
}
@local1 host local1.mydomain.com
handle @local1 {
reverse_proxy 192.168.1.101:8001
}
}
The "clever" bit is the matcher in the middle (second mistake). The idea: "if the request came in via the tunnel (port 9999) AND the host isn't on my public allowlist, kill it." This way I get split-horizon DNS while only having to maintain one single local Caddyfile.
I did a SINGLE (third mistake) quick test from my phone on cellular: public1.mydomain.com loaded, local1.mydomain.com returned a connection error. I went to bed feeling like a genius.
Fast forward about two weeks. I was out and accidentally tapped local1.mydomain.com on my phone. It loaded instantly.
I aged five years in about ten seconds. For the past two weeks, anyone who had bothered to enumerate subdomains on the VPS could have walked straight into my LAN, including services with zero authentication (you know which). So much for the elegant solution.
The cleanup afterwards was time consuming. I yanked the VPS tunnel, rotated every credential I could think of, scoured Caddy access logs (thank god I had them on) for anything suspicious, and spent a solid hour combing through logs of my unprotected services.
In the end I think I got away with it because nobody bothered to brute force my VPS (which was also protected by crowdsec), but "security through nobody-bothered" is not a posture I want to be in.
Explicit blocking on the VPS side is non-negotiable. The little maintenance overhead is worth it for the security benefits. Another benefit is that it minimize useless traffic hitting my local server. I wasn't able to pinpoint what was wrong with my "clever" expression, so just ended up scrapping it and added the following line to the VPS Caddyfile: @public header_regexp Host ^(public1|public2)\.mydomain\.com$. Yes I'm still very lazy here with the concise regex, but this time I made sure to test it correctly 😅
"It worked when I tested it" is not the same as "it's doing what I think it's doing." Test both the happy path AND the path that's supposed to fail, from outside, more than once. One green light is not a security audit.
Protect local services with authentication. Even a simple HTTP auth layer would have saved me a lot of stress here, and it's not like I don't have the tools to set it up. I was just too lazy and thought nothing could ever happen.
This incident has been a wake-up call to my complacency and lack of rigor when it comes to security. Post the story and the broken config above as the cautionary tale. Don't be me 💀.
⬆️ 341 points | 💬 76 comments
https://github.com/heyPuter/puter/
⬆️ 242 points | 💬 61 comments
Published: 1 month ago | Author: System
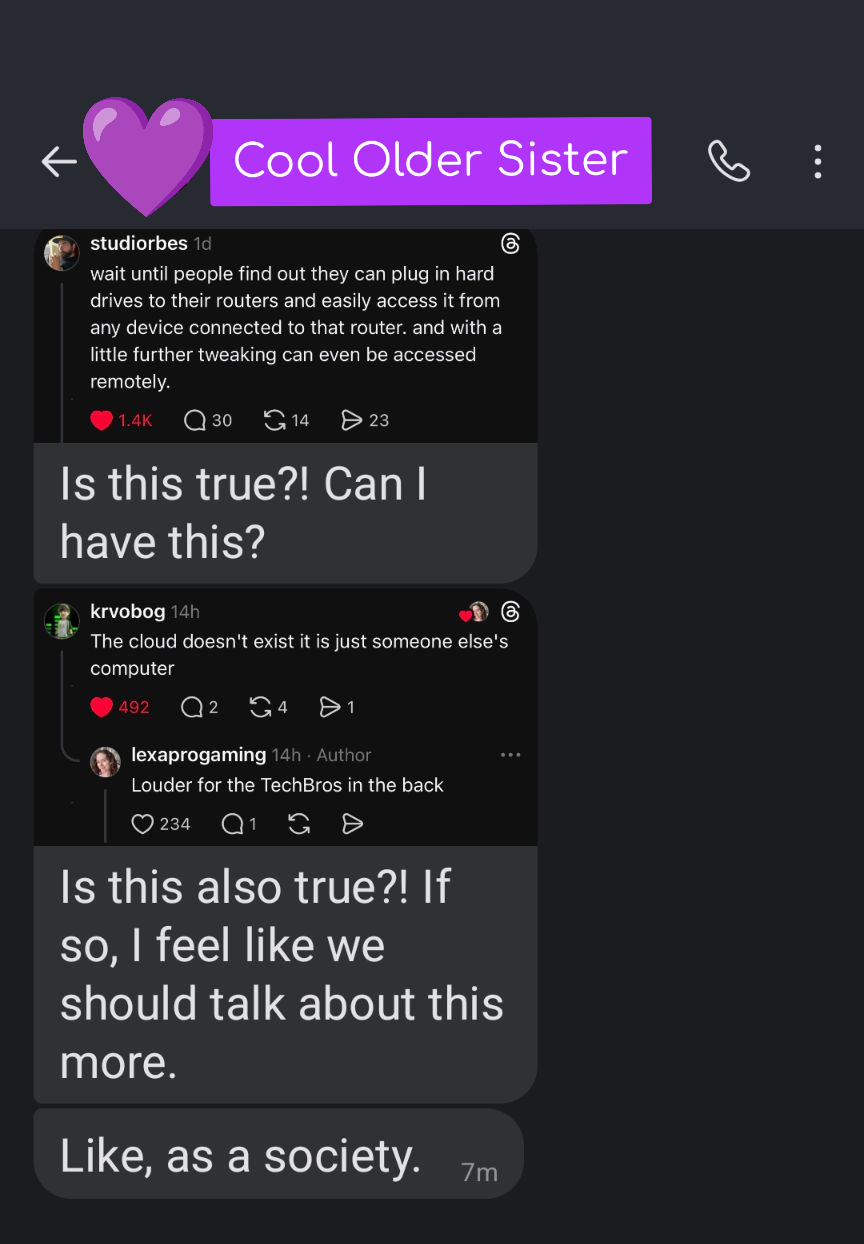
Buckle up sis, that's just the top 10% of the iceberg.
⬆️ 997 points | 💬 65 comments
CopyFail just dropped, it's a new Linux kernel vulnerability that gives attackers root privileges. https://arstechnica.com/security/2026/04/as-the-most-severe-linux-threat-in-years-surfaces-the-world-scrambles/
Debian has an updated kernel, Proxmox too. Looks like Raspberry Pi hasn't released an updated version yet.
⬆️ 366 points | 💬 162 comments
⬆️ 399 points | 💬 42 comments
https://github.com/dani-garcia/vaultwarden/releases/tag/1.36.0
Security fixes
This release contains security fixes for the following advisories. We strongly advice to update as soon as possible.
SSO Login CSRF - GHSA-pfp2-jhgq-6hg5, GHSA-w6h6-8r66-hcv7
User/Organization Enumeration - GHSA-hxqh-ff5p-wfr3
SSO existing-user binding - GHSA-j4j8-gpvj-7fqr
GHSA-6x5c-84vm-5j56
SSRF via Icon Endpoint - GHSA-72vh-x5jq-m82g
Some crate's updated and other minor security enhancements
These are private for now, pending CVE assignment.
https://github.com/dani-garcia/vaultwarden/releases/tag/1.36.0
⬆️ 254 points | 💬 14 comments
So my nas is getting big now slowly with around 8tb of data.
I run it on raid 1, but I wonder in the worst case scenario, I wanted to also have a off site backup. But obviously 8tb + on cloud is going to be expensive no?
How are you guys storing your offline backup? And where do you guys store it?
⬆️ 264 points | 💬 196 comments
The Point: Holy shit LXCs are so cool and felt like black magic getting "free" RAM back. If you're newer, like me, and have just been using VMs instead of LXCs, you should look at changing that.
I started my server back in November knowing absolutely nothing about using Linux, using CLI, or Docker. At the same time, I also went in raw, jumping straight into Proxmox on three nodes. As a result, I ended up using a lot of the Proxmox VE Helper Scripts for initial setup and have since gone back and learned how to do a lot of things myself. One of the hugely inefficient decisions I made at the time was to use a VM for Docker instead of an LXC.
For context, two of my nodes are running an i3-5005U and 8gb of soldered DDR3 RAM. One of those machines was exclusively running a VM to run Docker containers largely centered around downloads. On average, I was hitting ~30-50% CPU on the PVE host and ~7GB RAM usage.
Switching to an LXC has brought that down to 10-25% CPU and ~2-2.5GB RAM usage. A machine that felt like it was at its limit suddenly gained immense amounts of headroom.
Just wanted to put this out there for anyone procrastinating switching some VMs to LXCs. In my case, it was worth the relatively low amount of effort to free up such a significant amount of resources.
⬆️ 251 points | 💬 83 comments
These two are the most incredible technologies on the modern Internet. The Web is finally free and open again, just as Tim Berners-Lee intended it so many decades ago at CERN. People are finally taking the Web back from corporations, and it is amazing to see. Tailscale is going to be the biggest tech company in the world by the next decade, and the GTA will overtake the Bay Area as the world's tech capital.
⬆️ 232 points | 💬 75 comments
Published: 1 month ago | Author: System
https://www.reddit.com/gallery/1swsb7o
After a lot of trial & error (and a few docker restart moments 😅), I finally got my dashboard where I want it:
All running on a Raspberry Pi 5 with a clean and optimized Docker stack.
Still a work in progress (because let’s be honest… a homelab is never “finished”), but it’s already my daily control center.
What would you add next? Any ideas for the next upgrade?
⬆️ 333 points | 💬 37 comments
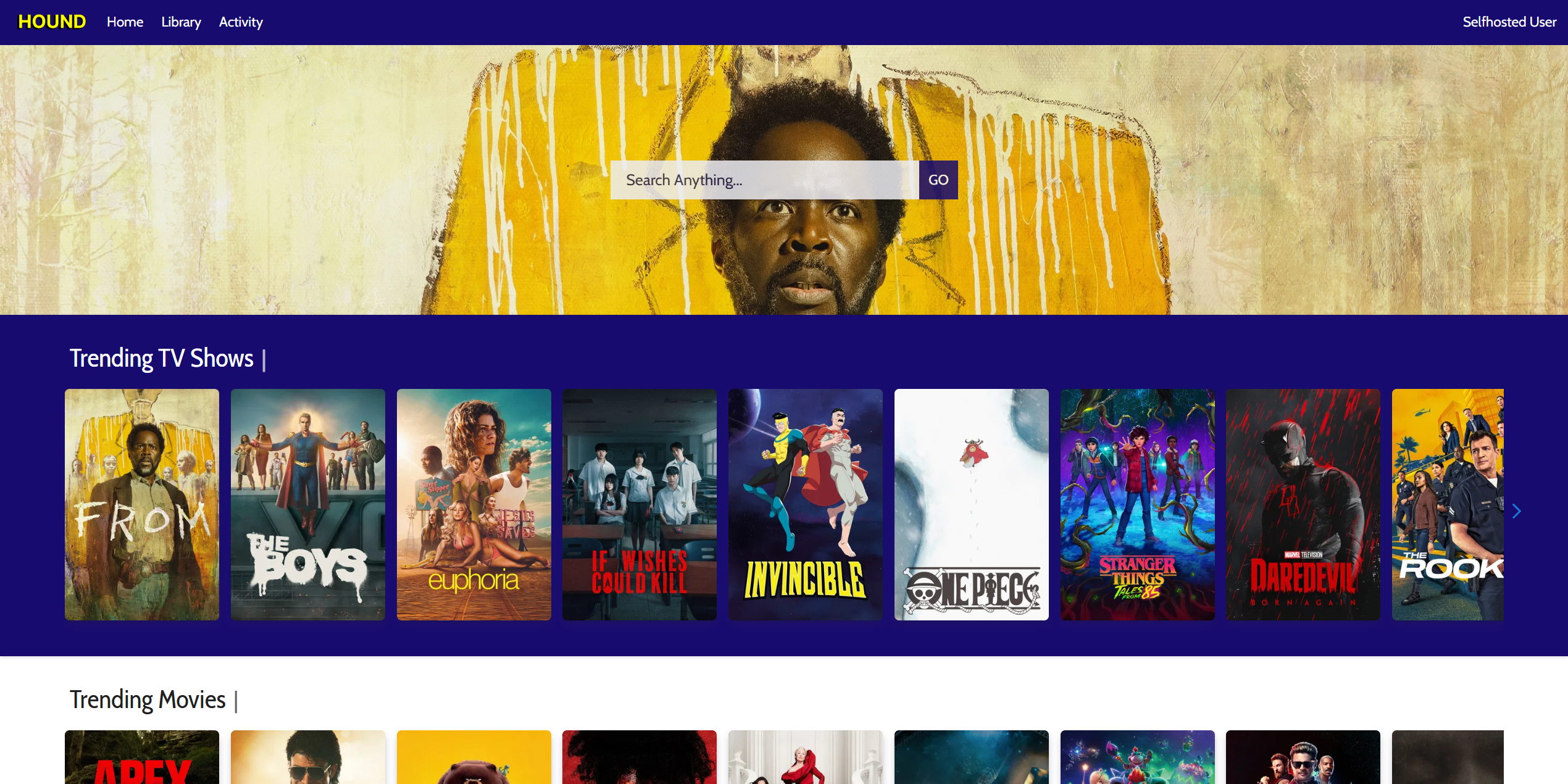
What is Hound?
Hound is a self-hosted, open-source media server, like Plex/Jellyfin, but with the extra ability to stream content through P2P (torrent) or HTTP/Debrid without downloading first. With Hound, you have the flexibility of fully controlling your media like Jellyfin, but can also stream instantly ala streaming services. It's the best of both worlds.
I posted about Hound in this sub years ago, when it was originally built as a simple movie/tvshow tracker. Since then Hound has evolved into a full media server. Link.
Links
Features
Demo
Note that the web portal isn't optimized for mobile yet:
Access the demo here.
username: selfhosted
password: password
This is just the web portal, for actually watching content you'll want to use the apps
Platforms
Android and Android TV apps are available, you'll need to sideload the APKs. iOS and tvOS require a bit more time for testing and to distribute through TestFlight. They share the same code (built on React Native TVOS) so most of the effort is done.
Installation
Docker compose is the recommended way to install Hound:
services:
hound-postgres:
container_name: hound-postgres
image: postgres:18
environment:
POSTGRES_DB: hound_db
POSTGRES_USER: hound
POSTGRES_PASSWORD: super-strong-password
volumes:
- ./Hound Data/postgres_data:/var/lib/postgresql
healthcheck:
test: ["CMD-SHELL", "pg_isready -U hound -d hound_db"]
interval: 5s
timeout: 5s
retries: 5
hound-server:
container_name: hound-server
image: houndmediaserver/hound:latest
depends_on:
hound-postgres:
condition: service_healthy
ports:
- "2323:2323"
environment:
- POSTGRES_DB=hound_db
- POSTGRES_USER=hound
- POSTGRES_PASSWORD=super-strong-password
- HOUND_SECRET=super-strong-secret
volumes:
- ./Hound Data:/app/Hound Data
# (Optional) attach your media library
# IMPORTANT: Please read the docs before doing this
# - /path/to/movies:/app/External Library/Movies
# - /path/to/shows:/app/External Library/TV Shows
POSTGRES_PASSWORD on both hound-postgres and hound-server servicesHOUND_SECRETThen run docker compose up -d
Access the web portal at port 2323:
http://<ip-address>:2323
username: admin
password: password
Make sure you change your password immediately.
Next, you'll want to set up a provider next to start watching content, refer to the guides below:
Why Hound?
When I set up Jellyfin for my friends and family, I found that they kept switching back to Netflix/Prime when it was more convenient. Today, the Plex/Jellyfin ecosystem is quite mature. But for some (especially older) people, using a separate app, requesting content first, and waiting a couple minutes (or even longer) can be unintuitive/inconvenient. It's much nicer to be able to scroll and discover content, and watch immediately in seconds.
From an admin perspective, drives are getting increasingly expensive, and larger libraries drive electricity costs even more.
My vision for Hound was to have all the advantages of self-hosting media, with the flexibility of streaming. You can still curate a library with whatever content you like, but for content not yet downloaded in your library, Hound switches automatically to P2P/Debrid streaming, so it's a seamless experience for users.
Hound is in Beta + Pricing
Hound is in Beta, so please expect bugs and run backups often. Although Hound is completely self-hosted and open source (AGPLv3), there will be a paid tier when Hound leaves beta:
Unfortunately, unlike the amazing maintainers at Jellyfin, I can't keep Hound free. I thought long and hard about pricing that respects self-hosting and open source philosophies. I settled on this model so anyone can try Hound and all its features for free, and have an informed choice on whether or not to purchase.
Since Hound is completely open-source, I can't stop you from forking and removing the license checks. Instead of doing this, if you contribute to Hound's development actively, I'll give you keys upon release.
You can't actually purchase yet since we're in Beta, but I wanted you to know in advance.
Please try the demo and leave feedback! If you like the project, please consider adding Hound to your stack, and even contributing!
⬆️ 228 points | 💬 96 comments
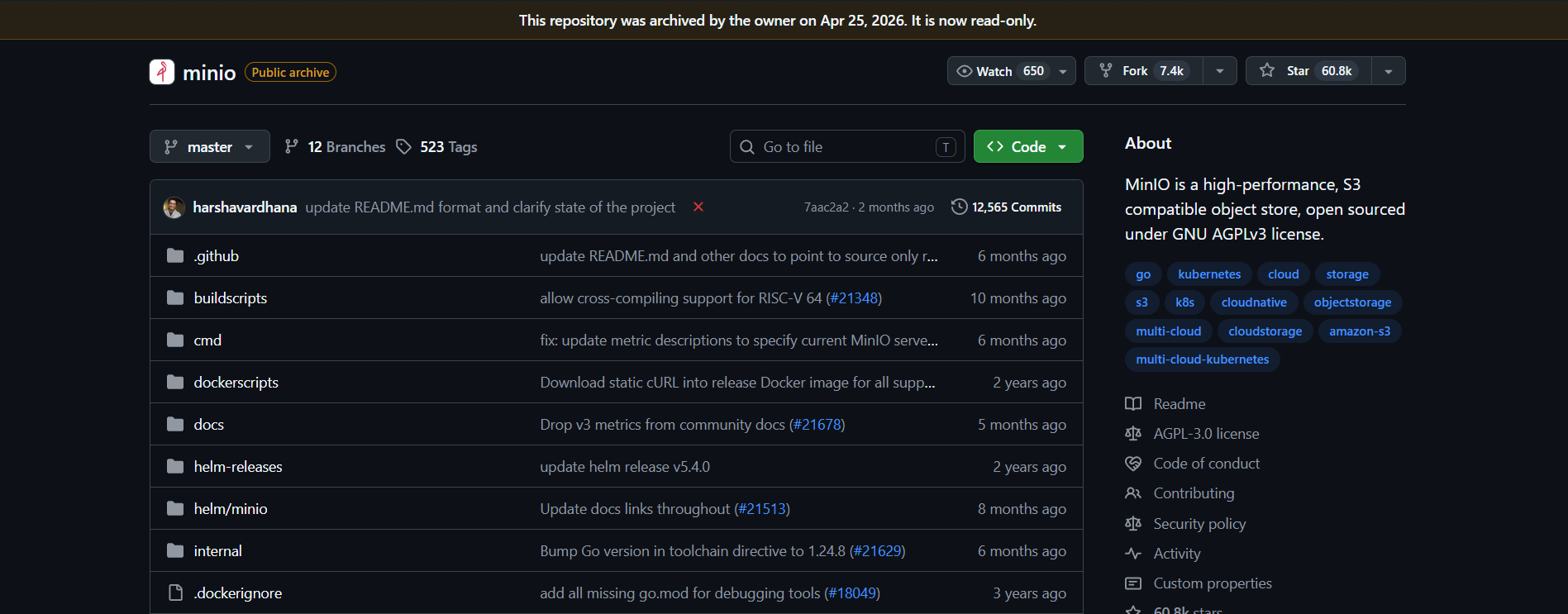
Just learned about S3-style object storage and was looking into self-hosted options for my homelab. Came across MinIO and got pretty excited because it seemed like exactly the kind of thing I’d want to learn and maybe use.
Then I noticed the repo is archived, which was a bit discouraging.
I know that doesn’t necessarily mean the software is dead, but it made me pause before building around it.
For those using MinIO, would you still adopt it today for a homelab? Or would you look at alternatives instead?
Curious what people here are doing.
⬆️ 310 points | 💬 62 comments
The title took me a while to land on, but the thoughts behind it have been sitting in my head for months. I've been into homelabing since early 2020 with my first build, then a second, then a third, then whatever my bank account allowed after that. It's been a lot of fun and tears. But lately browsing this community has had a edge to it, a lot of AI negativity that I mostly understand, and that's what I want to write about.
I'm a programmer by trade, actually army before, but released and went back to school. The usage of AI at work has increased and I don't see that trend stopping quite yet, AI is useful as a companion to handle tedious tasks like documentation, reviewing SQL, tedious front-end markup, one shot scripts etc.. But using it to one-shot a whole application is risky and if published downright irresponsible and this is where I think most of the friction is happening, at least for me.
When I see the AI projects posted here, with my experience, I think I can separate the wholly vibe coded ones from those that AI was used to assist, the latter I don't mind, despite what some Luddites say, that's what the industry is like now. When you code something for your own use, the blast radius is limited, thing could run horribly and it won't matter, you are the only one that suffers the consequences, but if you publish this code you need to take ownership of it and ownership brings responsibilities that you need to shoulder. Even as a programmer I don't take this lightly, this is not something people should dismiss with the command git push origin main.
It's one of the reasons I don't publish my stuff, or at the very least don't advertise it, not because it's vibe coded, it isn't, it's because I still need to take responsibility for it, that's time, effort and commitment that shouldn't be underestimated (many seems to). Maintenance is not a trivial affair, thinking about current and future users, how you approach breaking changes, how you architect things to avoid breaking changes as much as possible. Continuity of the project is also important, if you take your project seriously and your user base seriously you should have this in mind : "What if I can't continue the project?", archiving the repo and disappearing is not the right way to do things.
So, before publishing and parading your project, you just need to ask yourself a simple question : "Can I take ownership and responsibility for this code". The answers will depend on your definitions of these concepts, but if you think about it for more than 5 minute, you might just realise your project should stay private.
PS: Here I am talking more about the moral/ethical implications when I talk about responsibilities and ownership, you are obviously responsible for what run in your machine. Excuse some awkward syntax or phrases, non native English speaker.
⬆️ 230 points | 💬 87 comments

So I have been working on my personal portfolio website for some time now, I had since forgot about it and had no motivation to expand it. I have been looking for the perfect usecase for my Pi Zero 2W, after moving my Pi-hole server from it onto my new Pi 5.
I then saw this post: https://www.reddit.com/r/selfhosted/comments/1sqvujn/selfhosted_public_website_running_on_a_10_esp32/
And it honestly got me excited to update my site, and move everything over the Pi. It is certainly much easier to run my site, from a measly 512KB of ram to just about 512MB.
The site is finally in a state where I feel comfortable sharing it, and I hope you guys like the aesthetic. There is a guestbook to sign as well :)
Site:
https://spellbound.sh
⬆️ 220 points | 💬 19 comments
Hey, here's the HortusFox dev again.
I got inspired by Dan Brown's decision to abandon discord for a hosted zulip instance. And then it hit me...
Back in the day, software projects had a website, documentation and forum. Some had, in addition, an IRC channel somewhere. This just worked. It was an amazing way to foster community and keep control over your data.
So, today I was very unhappy regarding enshittification again. I mean, we used to have soooo many platforms and sites back in the day. Now everything takes place on a handful of platforms. Internet monopolization by corporations. I know, this is no recent news. We all know that.
I believe forums may be a key aspect to regain digital sovereignty again. That's why I've decided to setup a forum infrastructure for HortusFox. When tinkering around, I eventually decided to go with Flarum. Simply because it's easy to install, uses the well-established Laravel framework and I like it's style from the ground without any additional extensions installed.
The selfhosted community is one of the most aware communities when it comes to data protection and digital sovereignty. I love that! That's why I once again decided to post here. ❤️
As for me, I am now going into the process of migrating from discord to flarum. I mean, discord feels great, it offers many features, but it's eventually centralized, it only has closed communities in terms of SEO and recent decisions in terms of age verification are concerning. The latter one is also a reason why I finally abandoned publishing play store apps three years ago, and went fully PWA. Microsoft Store does the same now (removed sign-up fee in favor of ID verification).
Maybe I'm a bit carried away, but imagine, if even the reddit communities such as r/opensource or r/selfhosted would abandon reddit in favor of a forum-based communities run by volunteers? Reddit is not our friend. And various decisions to wipe out third-party apps and pushing echo chambers aren't really something I consider "the heart of the internet". By the way, did you notice Reddit now tests forcing people to use the mobile app when they browse reddit via a mobile browser? Pretty sure, they will eventually rollout this "feature".
What do you think? Both developers and selfhosters, would you like the idea that we turn back to forums again?
PS: HortusFox now also officially backs the open-source petition to have the german government acknowledge opensource work as volunteering by law. A big thanks to Boris Hinzer for launching the campaign.
⬆️ 203 points | 💬 43 comments
Hi there, I’m iSponsorblockTV’s maintainer.
If you’re running iSponsorblockTV, you’ll need to pair your devices again since YouTube have changed the screenId format and are on the process of revoking all older codes.
For those of you that don’t know, iSponsorblockTV allows you to use SponsorBlock on all YouTube TV devices (TVs, sticks and consoles). It can also click the skip button for you and mute native YouTube ads.
Sadly there’s nothing that can be done on my part other than pairing devices again.
EDIT: the new screen id will be 64 hex digits long, compared to the old 26 characters
⬆️ 197 points | 💬 18 comments
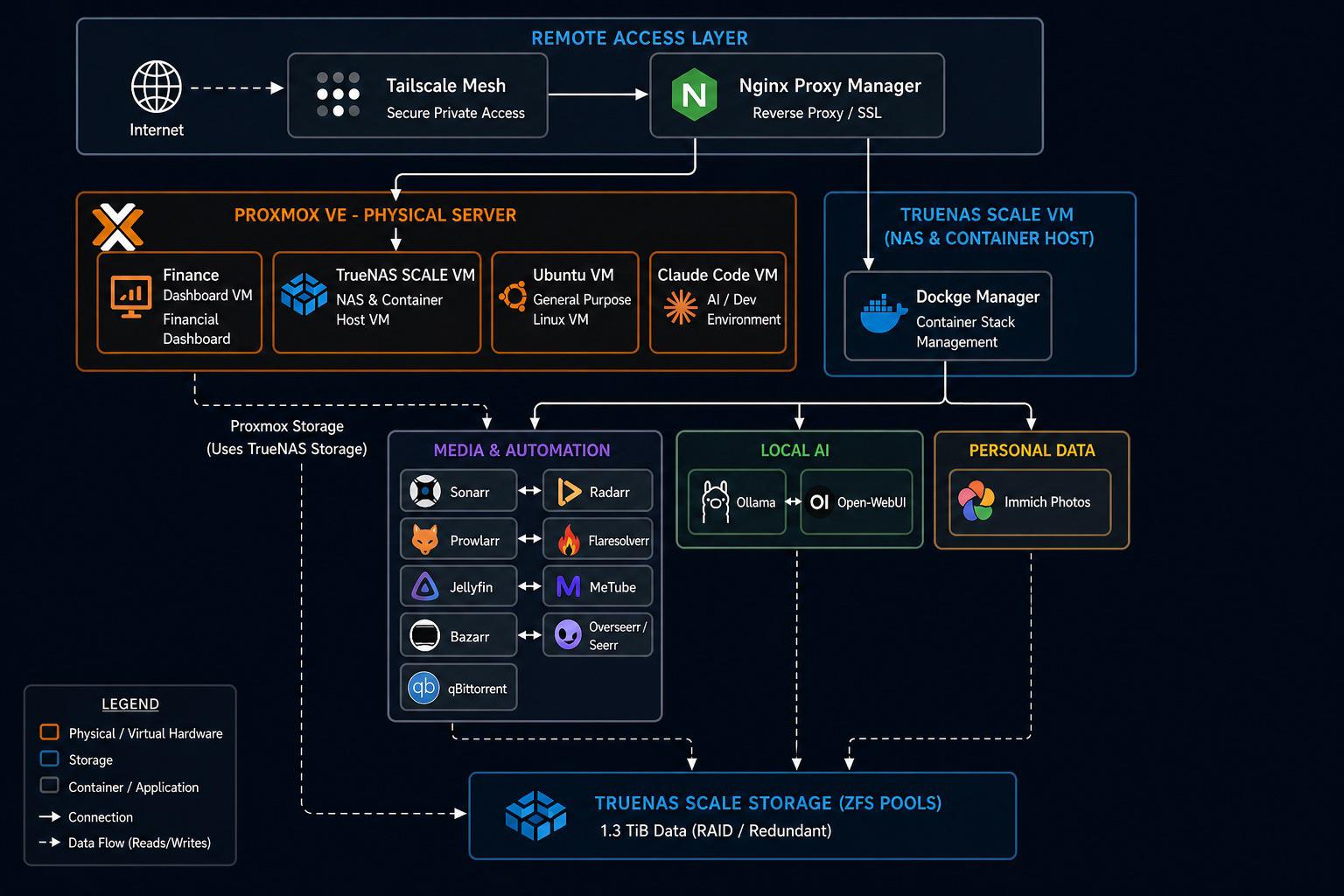
This is my setup. Image made by AI but overall looks like this. There is no connection between proxmost host and media but proxmox uses my truenas storage (16TB). I removed everything. Nginx isn’t connected anymore. Everything is LAN. Started homelabbing in Feb with no background.
Watched a lot of videos and read too many posts on here. I run apps I vibe code for personal use.
⬆️ 200 points | 💬 42 comments
Published: 2 months ago | Author: System

My homelab does have the usual rack of stuff (Dell Poweredge R730s and ECU servers), but this one ESP32 sits separately on the wall and serves a public website entirely by itself. No nginx or apache, no Pi, no container... just a $10 microcontroller holding an outbound WebSocket to a Cloudflare Worker that fronts the traffic.
The original launch of this back in 2022 ran for ~500 days before the original board burned out in 2023. The site sat as a read-only archive until now. I relaunched it after rebuilding it from the ground up with a lot of redundancy in mind such as a Worker relay, daily off-site backups to R2, and more, check out the project's README.
Site: https://helloesp.com
Code: https://github.com/Tech1k/helloesp
---
Update: So slight miscalculation on how popular this was going to get, this was a good stress test of the ESP to say the least. The hug of death hit way harder than I anticipated lol
I believe the ESP32 has fully crashed or it's exhausting heap in a loop. It's not even showing up on my router now. The Cloudflare Worker is still serving the offline page in the meantime which is expected. Probably not the best idea to have made this post while I was at work and away from it. I will reboot and investigate this when I'm home and make adequate changes to get it back online and stable!
Update to the update: it has risen from the cold grasp of offline darkness and reconnected as the WiFi watchdog kicked in and rebooted it automatically. Requests are getting served again and I managed to regain access to it on LAN. Cloudflare is back to showing timeouts for some while others get through (expected behavior). I may lower the SSE cap and raise the min heap threshold. It's back to just getting overloaded at the moment. I will investigate further and see what I can make changes on later to help keep it afloat and serve more requests on 520KB of ram lol
⬆️ 467 points | 💬 35 comments
https://socket.dev/blog/bitwarden-cli-compromised
Same as the title. The Bitwarden CLI has been compromised and it would be good to check your stuff. I know how popular Bitwarden is around here.
⬆️ 723 points | 💬 152 comments
so i've been telling this client for 2 years their site was slow because of shared hosting
they finally listened after a competitor started ranking above them on google
moved them to a KVM VPS, same wordpress stack, nothing else changed
page load went from 3.2 seconds to 0.9 seconds. that's it. that's the whole story
the amount of money they lost over 2 years because they didn't want to spend an extra 15€ a month is genuinely painful to think about
if your site is on shared hosting and you're wondering why it feels slow, it's that. it's always that
⬆️ 338 points | 💬 32 comments
Something that’s really bothering in the last years is how much we’ve allowed information to be gatekept by Discord, especially in the selfhosting scene.
10 years ago if you ran into a problem installing software, you could just go to the devs forums and look for someone who already had this problem solved.
Nowadays you have to join a discord server, use their shitty search bar, don’t find what you want, and ask a burnt out dev who already gave out the same answer a million times.
From this observation I’m wondering the following question: would you use an open-source forums solution you can deploy in seconds, ready to use out of the box?
I already built an MVP of something like that mainly as an addition to my portfolio, but I’m now wondering if I should bother packaging it into a “one-click” deployment to be used by other people.
The concept is a minimalist & modern app to be used for small communities, events, or even friends & family. It is completely usable out of the box, yet still really customizable, with a nice search bar to actually find the stuff you want.
I’m not selling anything, I genuinely want to know if the data gatekeeping is a concern for you too, and if you would be interested in a solution like this for your own needs.
(also there is no vibecoding here, it’s a legit project for me to learn and develop my dev career)
⬆️ 351 points | 💬 204 comments
Most of us start by slapping a reverse proxy (like Nginx Proxy Manager or Traefik) and maybe Tailscale or Wireguard on our setups. But for those of you exposing specific services directly to the web, how far do you take your server hardening?
I usually stick to a strict baseline (Fail2Ban/Crowdsec, UFW, disabling root SSH, key-only auth, and isolating apps in Docker containers), but I’m curious about the more advanced layers. Are any of you actively running SOC-level monitoring, Wazuh, or strict SELinux/AppArmor profiles on your homelabs?
What is the one security measure you think the average self-hoster overlooks until it's too late?
⬆️ 364 points | 💬 187 comments
Hi all, it's been a few months and we've made some incremental updates to LubeLogger over that time.
In case you've never heard of LubeLogger, it's a self-hosted vehicle maintenance and fuel mileage tracker, you can log your service records and fillups in here and it will tell you exactly how much you've spent your vehicles.
First, as stated in our previous post here with the big UI update, we were going to start converting the grids in mobile views to cards, which makes it a lot easier to see all data without horizontal scrolling on small vertical screens, and that's finally delivered. If you prefer the older grid view in mobile, there is an option to revert in the Settings page.
Second, there are now real-time notifications built within the app, if you follow us on the r/lubelogger subreddit, you might have heard of a daemon service that needed to be deployed separately, well that's no longer the case as we have integrated the daemon features into the LubeLogger app itself. Real-time notifications will allow you to immediately be notified when a reminder has its urgency changed to an urgency that you're tracking(i.e.: a reminder went from Not Urgent to Urgent), and it can be integrated with nearly every notification service out there as long as they take a HTTP POST request(there are samples for NTFY, Gotify, and Discord in the Documentation), if you don't wish to use an external notification service, it can also be configured to use the pre-existing SMTP settings.
As part of this, there are also Automated Events that you can now configure, some examples of what you can do with Automated Events:
Here's what the automated backup email looks like:
Third, there is now a smoother way to onboard OIDC users with SSO-specific registration options
Misc. Improvements:
CSV's are now validated before any imports are performed, and it will tell you what went wrong/was formatted wrong:
You can now add multiple recurring reminders to Plan Records and you can modify which reminders are tied to these plan records all the way up until the plan is marked as done
On that note, there are now QR Codes that you can generate that can either take you to a specific record or to add a new record:
If you want realtime events coming from LubeLogger but you don't want a webhook integration, you can now use web sockets which works on a pub-sub model.
Anyways, that's it from us for this update, have a great Summer and we'll see you in Fall.
⬆️ 339 points | 💬 47 comments
I setup the hagezi ultimate adblock list in pihole a few months ago and didnt think much of it after that. Today I am chilling and trying to avoid working too much on a Friday afternoon when I get an alert from uptime kuma that my nginx-proxy-manager stopped responding.
I check the docker container first, everything is green and logs look fine, weird but lets restart it just to be sure. No change, hmmm well I can access the demo page at the direct IP so maybe its not this, lets check the DNS resolve.
> nslookup proxy.homelab.com
Server: 10.0.1.66
Address: 10.0.1.66#53
Name: proxy.homelab.com
Address: 0.0.0.0
Name: proxy.homelab.com
Address: ::
Odd that should be resolving to the 10.0.1.66 server not 0.0.0.0 I wonder what changed. I dig around in the Pihole logs for a bit and discover that my domain was actually added to the offical blacklist. I am not really sure how since my public footprint is minimal, gets virtually zero traffic except for some bots to the root domain, and definitely doesn't serve ads. Either way I was able too lookup the commands to white list my domain in Pihole and bam everything was back to normal.
Just some friday fun.
⬆️ 333 points | 💬 54 comments
Sharing something I've been running for a few months that's become one of the most useful things on my homelab.
The stack:
What it does:
Six n8n workflows that run on schedules and replace what I used to do manually every week:
Architecture notes:
The stack runs entirely on self-hosted n8n. No recurring SaaS costs beyond SimpleFIN (~$15/year) and Anthropic API calls (~$0.01/100 transactions). Everything else runs on your own infrastructure.
⬆️ 307 points | 💬 106 comments
Published: 2 months ago | Author: System
⬆️ 1,167 points | 💬 29 comments

⬆️ 417 points | 💬 75 comments
https://www.reddit.com/gallery/1sie9qy
When I started Borg UI, it was a personal problem. I needed a reliable way to back up my Immich photo library. I knew how critical backups were, and I wanted something I could actually trust. Four months, 1,100 stars, and 150k Docker pulls later, here we are.
Thank you. Genuinely. Every star, issue, and kind word kept this going. ❤️
What's been happening under the hood
Over the past few months I've closed 250+ issues, pushed combined test coverage to 64% (backend 58%, frontend 81%), and built out smoke tests, integration tests, and unit tests across the stack.
I have 10+ years of software development experience and code quality matters deeply to me. AI helped me move faster on glue code and boilerplate, but every critical path has been manually tested and reviewed. This tool runs on production data. I treat it that way.
Introducing Borg UI 2.0
Website: borgui.com
Docs: docs.borgui.com
Github: https://github.com/karanhudia/borg-ui
Old Post: https://www.reddit.com/r/selfhosted/comments/1p5fg68/borg_ui_web_interface_for_borgbackup_for_your/
If Borg UI has been useful to you, a star ⭐ on GitHub goes a long way. And if you have feedback, ideas, or just want to say hi, I'm here.
Thanks for being part of this.
CONTEXT (FROM OLD POST): I had been using BorgBackup via command line for a while to create backups of my Immich library (self-hosted photo management tool). It felt very tedious to continuously monitor, and maintain while creating a backup, scheduling or restoring, especially via SSH. I have docker containers for everything else, so I thought why don't I put together a Web UI that makes it easier to manage.
It runs as a Docker container (no config needed).
⬆️ 433 points | 💬 104 comments
https://www.reddit.com/gallery/1sitp0y
Hi. So... a little while back I lost my job and then shortly after had a pretty serious injury that required surgery and months of recovery.
During that time, a family member asked if I could help go through decades worth of old hardware they had lying around and figure out what to keep, what to donate, and what to get rid of. It gave me something to focus on.
What started as simple inventory work slowly turned into something else.
I began trying to revive old machines - figuring out what each one was still capable of, what its "best use" might be, and how far I could realistically push it. Along the way I found a bunch of Raspberry Pis doing nothing, old laptops collecting dust, old hard drives that were either dead, decaying or somehow in perfect working condition despite having 50k+ power-on hours (made sure to stress test them with `badblocks`) and all sorts of forgotten gear that still had some life left in it.
I realized I actually really enjoy working within constraints - taking modest, mismatched hardware and trying to squeeze something meaningful out of it.
So... this is the result of about 4–5 months of that process.
It’s not the most powerful homelab by any stretch. I'm sure many of you are running far more capable setups and the Macbook Air that I'm posting this from can run circles around the hardware in the setup, but that wasn’t really the goal. This was more about experimentation, iteration, and seeing what I could build with what I had.
And with that, here’s the current state of my humble homelab. I'd love to hear your thoughts, roasts, advice or questions if you have any.
This setup is by no means in it's final state. For instance, I've been working on moving some of my infrastructure over to being managed by Kubernetes, such as my project "x", which will one day live in the cloud. This homelab is already far more cohesive than anything I’ve built before - mostly because in the past I was always prioritized work-related needs rather than my own setup. While my body has healed, I am still looking for work in this challenging tech job market and, therefore, have the time to continue iterating and refining.
PS: There are some things I didn't cover, because it was getting too detailed. For example, on every machine that has a hard drive, I also have a docker stack that monitors SMART, does drive health analysis and routine scheduling of drive tests and more - a tool I plan to release as OSS, because I wanted something a little different (more advanced) than Scrutiny (Python/Flask + JS front-end... maybe rewritten in Go some day). Stuff like that, but I might post some more detail in the comments if anyone is interested.
Also, for context on the “physical infrastructure”: everything is running in a basement workshop inside a converted storage closet.
To deal with heat, I ended up improvising an extraction system using an old workshop fan mounted inside a cut-up plant pot, wired to a switch. It’s very much a MacGyver solution, but surprisingly effective at keeping air moving and temperatures under control (all hard drives stay at a comfortable 40-45°C / 104-113°F under normal load and stays in the safe zone when under heavy load).
Anyways, thanks! Have a great day!
⬆️ 442 points | 💬 48 comments

Sorry for a such a depressing title and the post. I just wanted a space to air out my frustrations and my sadness.
First before I get to my depressing part, I want to talk about my journey. I got intrested in self hosting during my undergraduate studies, graduated at 2024 and started this journey, initially I did not want to spend any money on this and used the really old laptop as my NAS for my services and had it accessible only through private network.
Last month i decided to have proper setup, bought a thermal paste, new cmos battery cleaned up my laptop and also bought a domain and setup cloudflare tunnel(I don't have a static IP).
Things were going good for a month but then issues started to occurred, the system heats to 71C, before fresh paste it heats up to 90C, found the problem to the exhaust fan. Then it was the failing harddisk and ram problems and system generally being extremely slow due to aging hardware.
With the current RAM prices and Storage generally being extremely costly. It is massive investment and my current salary cannot even afford it.
Again sorry for such a depressing post and I wanted to thank this community for all the help and resources it provided me to even start this journey learnt alot guys. Looks like my journey ends here.
Thank you.
⬆️ 369 points | 💬 88 comments
Free tier users bumped from 3 to 6. Smart move because the difference between 3 and 5 was why I started on Netbird for my household.
Official Annoucement: https://tailscale.com/blog/pricing-v4
⬆️ 376 points | 💬 65 comments
I’m still pretty new to self hosting and I thought this could be a useful question for people like me too. What mistake taught you the most once you got into self hosting?
Edit: Thanks a lot to everyone here, I really appreciate all your advice!
⬆️ 346 points | 💬 356 comments
https://www.reddit.com/gallery/1smsed9
So I've been using karanhudia/borg-ui for a few months now, very happy about it.
I recently upgraded to the newly announced v 2.0 and all I get is spam about upgrading to a Pro version, and how seemingly now I have a limited trial left.
What the heck? this app is built entirely using open source technology, and now the author is deciding to charge for it?
Has anyone considered forking? Or is there a truly FOSS community alternative?
I'm tired of using borgmatic, I need a decent solution to schedule borg backups in my NAS. I can't possibly be the only one in this situation. Any thoughts?
edit: alternatives found in this comment
edit2: author answered here
⬆️ 372 points | 💬 172 comments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}